ODBC: The Unix Story
Tim Haynes, OpenLink Software, Tue Jun 3 09:09:38 2003
What is ODBC?
ODBC is a system for providing an abstraction on top of database access, transferring SQL and meta-data queries to the database and conveying the results back.
From the end-user perspective, one application can be used quickly, easily and uniformly against many different backend sources of data.
From the programmer's perspective, ODBC is a C-based API that saves time and effort writing applications. Instead of writing using native access methods for Oracle, Sybase, PostgreSQL etc, you write once against ODBC and point the data-source wherever you desire at run-time.
From the system administrator's perspective, it's just another small package to maintain.
A Walk-through of ODBC Components
Starting at the top, an ODBC application needs to invoke the Driver Manager component - normally this involves being linked, either dynamically or statically, against libodbc.so or libiodbc.so.
<img src="ODBCOnUnix/docs/images/arch3-small.png" alt="ODBC architectural overview graphic">Because of the generic nature of ODBC, an ODBC application should not be written with any particular RDBMS product in mind for the backend.
The Driver Manager handles all the calls the application makes - such as "what data-sources do you have?", "connect to ThatDataSource", "execute the query `select * from ThatTable;'", and so on. For this reason, the application should be linked against libiodbc.so or libodbc.so, in order to provide all the SQLsomething() functions.
The most useful ODBC calls the application will make involve using a specific driver to connect to a specifc backend database. The Driver Manager's job is to load the appropriate driver and pass the relevant ODBC calls straight to it.
The ODBC driver itself makes a connection to the backend database; this is normally possible through either a Unix socket or using TCP/IP, optionally over a remote network to a different server. In the case of OpenLink Multi-tier drivers, this driver can involve multiple components - a generic client, a request broker on the server and a database agent to handle the connection, adding extra levels of security and better performance.
It is the driver's responsibility to pass queries on to the driver in a syntactically valid form (for the level of SQL compliance the driver claims to implement) and maintain integrity when conveying the results back. It also adds value to the connection, however, in that much meta-data about the driver and the database can be used dynamically. Also, transaction support is standardized and can be coupled with reusable (prepared) queries to increase performance significantly.
For example, suppose you wished to execute the SQL statement
insert into mytable values (99, 'Tim', '01-03-2003');
repeatedly, changing the values as you go. While it is certainly possible to generate varying statement strings in your application and then execute them, the database must compile and run the statement in entirety every time, taking locking considerations on the row or even whole tables into account. This is highly inefficient.
The alternative is to prepare a query of the form:
insert into mytable values (?, ?, ?);
then for each row intended, bind parameters to each of the place-holders, and repeat just the execution phase. If several rows are batched-up at a time and a transaction put around them, the net time taken can be reduced by an order of magnitude.
It is the ODBC driver's job to handle the binding of parameters here, and to control the transaction/isolation levels, etc.
Now you also have extra flexibility as an application writer; the above simple statement had an obvious ambiguity in the date field. Typically, databases vary in both the format of dates supported (and preferred for a particular database instance), and in the size and precision of timestamps. ODBC works around all this by providing the application author a metadata call to establish what the native name for a given type of field is - DATE or TIMESTAMP or DATETIME, whatever - and three unified escape-syntaxes, for date, time, and timestamp. The driver will then transform the escaped syntax into one the database is configured to understand with no ambiguity.
Installing ODBC
Driver Manager implementations
Unlike Windows, Unix has historically never come with a system-wide ODBC installation, therefore there is greater scope for setting everything up the way you wish.
Also on Unix, there are two main-stream implementations of ODBC: UnixODBC and iODBC. The former comes with a QT-based implementation of a GUI, while iODBC provides a GTK+-based administrator.
The iODBC package is available in several formats - source tarball, source RPM, and a choice of binary components. Installing the binary packages is a simple exercise - for example,
sudo rpm -Uhv libiodbc-3.0.6-2.i386-glibc21.rpm
will install the iODBC runtime library.
There follows an alternative, walking through an unpacking, configure and build of the complete sources from tarball:
zsh, purple 6:10PM C/ % tar xvpfz libiodbc-3.0.6.tar.gz libiodbc-3.0.6/ libiodbc-3.0.6/admin/ libiodbc-3.0.6/admin/Makefile.am libiodbc-3.0.6/admin/Makefile.in [snip] zsh, purple 6:10PM C/ % cd libiodbc-3.0.6 zsh, purple 6:10PM libiodbc-3.0.6/ % ls AUTHORS LICENSE NEWS bin/ etc/ mac/ COPYING LICENSE.BSD README configure* include/ samples/
Configuration, starting with a check of interesting options specific to iODBC:
zsh, purple 6:10PM libiodbc-3.0.6/ % ./configure --help Defaults for the options are specified in brackets. Configuration: -h, --help display this help and exit --help=short display options specific to this package --help=recursive display the short help of all the included packages [snip] --enable-fast-install=PKGS optimize for fast installation default=yes --disable-libtool-lock avoid locking (might break parallel builds) --enable-gui build GUI applications (default), --disable-gui build GUI applications --disable-gtktest Do not try to compile and run a test GTK program --enable-odbc3 build ODBC 3.x compatible driver manager (default) --disable-odbc3 build ODBC 2.x compatible driver manager [snip] zsh, purple 6:10PM libiodbc-3.0.6/ % ./configure --prefix=/usr/local/stow/iodbc --with-gtk --enable-gui && nice make checking for a BSD-compatible install... /bin/install -c checking whether build environment is sane... yes checking for gawk... gawk ...
Installation, starting with becoming root by sudo, then stow-ing the package tidily into /usr/local/:
zsh, purple 6:15PM libiodbc-3.0.6/ % sudo -s Password: zsh, purple 6:17PM libiodbc-3.0.6/ # make install Making install in admin make[1]: Entering directory `/home/tim/C/libiodbc-3.0.6/admin' [snip] make[2]: Nothing to be done for `install-exec-am'. make[2]: Nothing to be done for `install-data-am'. make[2]: Leaving directory `/home/tim/C/libiodbc-3.0.6' make[1]: Leaving directory `/home/tim/C/libiodbc-3.0.6' zsh, purple 6:18PM libiodbc-3.0.6/ # cd /usr/local/stow/ zsh, purple 6:18PM stow/ # chmod -R og=rX iodbc/ zsh, purple 6:18PM stow/ # stow iodbc/ zsh, purple 6:18PM stow/ # ^D zsh, purple 6:18PM libiodbc-3.0.6/ % ls /usr/local/stow/iodbc/bin/ iodbc-config* iodbcadm-gtk* odbctest*
Configuring DSNs
The graphical (GTK+-based) configuration screen makes setting up your data-sources (DSNs) quite intuitive, especially if you're used to the setup screens on Windows:
 An example of adding a new datasource follows:
An example of adding a new datasource follows: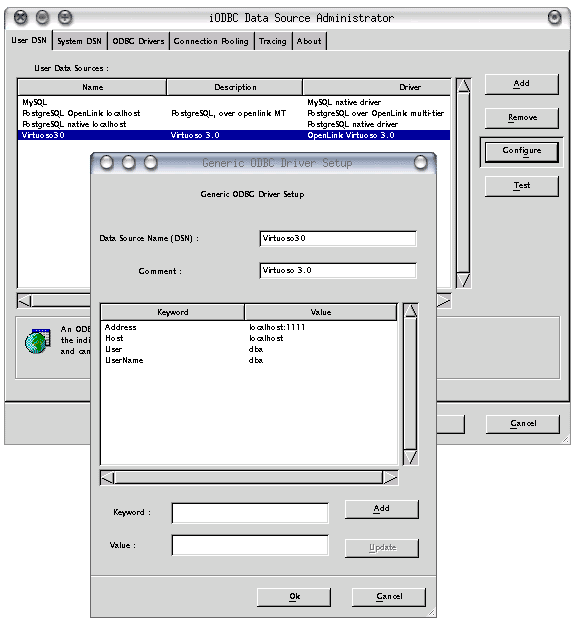
The real files
The iODBC library searches for its DSN through a set few files:
- $ODBCINI - the environment variable, if set
- ~/.odbc.ini - in your home-directory, if it exists
- /etc/odbc.ini - a system-wide default
The format of this file is very simple; there are 3 sections, one for ODBC itself (setting up tracing), one for a list of DSNs, and one for the definitions of those DSNs, thus:
[ODBC] Debug = 1 Trace = 0 DebugFile = /home/tim/temp/odbc-debugfile.log TraceFile = /home/tim/temp/odbc-tracefile.log TraceAutoStop = 1
[ODBC Data Sources] Virtuoso30 = OpenLink Virtuoso 3.0
[Virtuoso30] Description = Virtuoso 3.0 Driver = /opt/opl/virtuoso-o12/lib/virtodbc.so Address = localhost:1111 UserName = dba User = dba
Each DSN configured has an entry in the `ODBC Data Sources' section, and a complete definition in a paragraph section of its own.
There is also an ODBCINSTINI file; this contains descriptions of the ODBC drivers available.
[ODBC Drivers] OpenLink Generic = installed [OpenLink Generic] Driver = /opt/openlink/odbcsdk/lib/oplodbc.so
Making a test connection
To test that a DSN connects correctly, you can use the supplied `odbctest' utility.
zsh, purple 3:58PM bin/ % ls iodbc-config* iodbcadm-gtk* odbctest* zsh, purple 3:58PM bin/ % echo $ODBCINI /home/tim/.odbc.ini zsh, purple 3:58PM bin/ % ./odbctest iODBC Demonstration program This program shows an interactive SQL processor Enter ODBC connect string (? shows list): Progress9.x(solaris) | OpenLink Generic ODBC Driver Progress9.x(solaris) | OpenLink Generic ODBC Driver pgsqlPurple | PostgreSQL native driver pgsqlPurpleOpl | PostgreSQL using OpenLink driver pgsqlPurpleVirtDemo | Virtuoso database driver SQLServer | OpenLink Generic ODBC Driver Enter ODBC connect string (? shows list): DSN=pgsqlPurpleOpl Driver: 04.50.0801 OpenLink Generic ODBC Driver (oplodbc.so) SQL>select count(*) from timtest; count ----------- 100 result set 1 returned 1 rows.
Any of the DSN attributes can be overridden in the connect-string, which takes the form
DSN=dsn_name[;attr=value]*
The attributes themselves depend on the database driver behind the DSN; normally they control the username (where the attribute could be called`userid' or `uid') and password (if specified) used to connect to the database, some form of server hostname specification (`host=' or `server='), and a means to identify a database instance on that server (`database='). A driver may also have custom attributes, such as FetchBufferSize, Port, etc.
Known working ODBC applications
The following environments are where ODBC is commonly to be found:
PHP scripts, typically on a webserver: PHP itself contains no intrinsic native database-abstraction layer, meaning code has to be written against Oracle, MySQL, PostgreSQL, .. etc. ODBC to the rescue - PHP does support this as a backend.
Perl - typically found as a CGI script or using mod_perl, on a webserver: Perl does have the DBI for an abstraction layer, which makes writing scripts against a database uniform, and the syntax gels well with the language. ODBC is one possible backend here.
Ruby - another, object-orientated, scripting language with its own implementation of the DBI standard.
Open Office - this has the ability to interact with an ODBC data-source for its own database functionality; notably its address-book components are just another database.
An example of the API in action
Handling multiple versions
Over the years, the ODBC API itself has changed from version 1.0, through 2.5 up to 3.0 and latterly 3.5. The main changes from 2.5 to 3.5 have been the introduction of SQLSetStmtAttr() and related functions, instead of the older SQLSetStmtOption() and relatives; also, in 3.0 and above, support for Connection Pooling was added, cursor support was enhanced, etc.
Fortunately, it is the job of the ODBC Driver Manager component to ensure that function-calls made by the application in a given version of ODBC are mapped to the same version that the driver understands. It is also possible for the application to enquire on a more fine-grained basis, to determine which features are available in a driver, on a given connection and on a statement-handle, primarily through the SQLGetInfo() function call.
Visualising ODBC call sequences
The OpenLink `odbctest.c' application is a simple example C application written using the ODBC API. As an overview, the flow of control for connection, executing a simple statement and retrieving data is as follows:
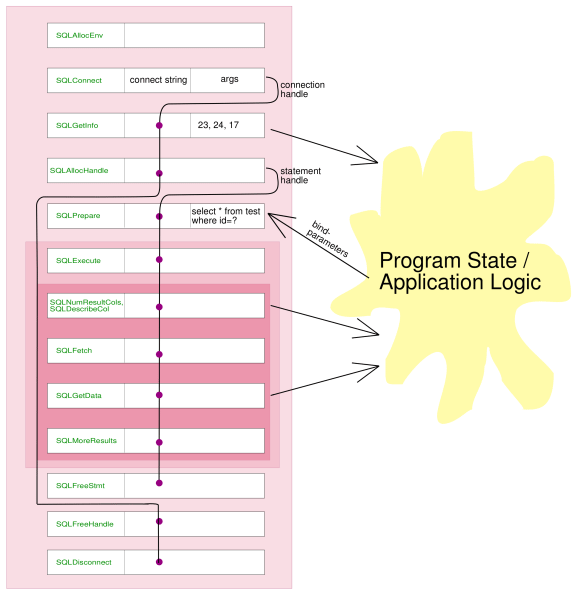 This diagram shows the following salient features:
This diagram shows the following salient features:- Functions from the ODBC API appear in the left element of each box.
- Arguments passed between functions are represented within each function's box. For example, the SQLConnect() function returns a `connection handle' entity which is then passed to subsequent function-calls.
- The SQLGetInfo() function-calls (three of them) return data about the nature of the connection, using the handle to do so: one for option 23 (cursor commit behaviour), one for option 24 (cursor behaviour during rollback operations) and 17 (SQL DBMS name). This meta-information is passed back to the application for use in further flow-control decisions.
- The SQLPrepare() function is used to tell the database to prepare a query for execution on a given statement handle. This statement may be re-executed multiple times with different parameters each time.
- After each execution of the prepared query, the number and types of the columnsin the result-set are determined, using the SQLNumResultCols() and SQLDescribeCol() functions. Then, while there are still rows remaining, SQLFetch() is called to return the next row, and SQLGetData() called to retrieve all the fields in the given row.
- After all the rows have been retrieved, a call to SQLMoreResults() is made to ascertain whether the query returned multiple result-sets or not. If so, the SQLFetch() + SQLGetData() loops may be repeated.
- Finally, the statement handle is retired with a call to SQLFreeStmt(), and the connection-handle destroyed with a call to SQLDisconnect().
There is scope for further enhancement as follows:
- Attributes may be set on the current connection, such as enabling or disabling auto-commit (by default, in ODBC, this is enabled on a per-statement basis), or setting the whole connection read-only.
- Multiple paramaters may be bound to the query, and their datatypes determined in real-time if necessary, by using SQLBindParameter() calls anywhere in the loops between SQLAllocHandle() and SQLExecute().
- Some databases only support binding parameters after the statement has been prepared; in order to use them beforehand, the application should make the relevant SQLGetInfo() calls in advance.
ODBC Application Considerations
Scrollable Cursors
Any real-time application has to be sensitive to changes in the data at the backend - the validity of any given query's resultset could potentially be quite short-lived.
Consequentially, ODBC provides various models of cursors, some implemented in the Driver Manager, others left for individual drivers to support.
The models of cursors available are:
- Static: this is a snapshot of a table, meaning it is insensitive to changes.
- Forward-only: this is sensitive to changes that occur prior to subsequent records being read; however, changes the previously read records are not affected.
- Keyset: a key set derived from unique record identifiers is used to fetch records into rowsets, so changes to any existing row will be observed, but this model is insensitive to record inserts and deletions; the keyset is built at cursor-open time, and it is larger than the row set which does the scrolling.
- Dynamic: the keysets are rebuilt for each row set, so there is the additional sensitivity to inserts and deletions which is missing from the keyset model.
- Mixed: the keyset is of configurable size such that keysets are rebuilt prior to rowset reaching their end points; this delivers more sensitivity than the keyset model, and less overhead than the dynamic model
Transaction Isolation levels
ODBC provides 4 levels of isolation for transactions. The following definitions are used:
- Dirty Reads: this occurs when a transaction reads data that has not yet been committed by another. It causes problems when the second transaction is rolled-back instead of committed.
- Nonrepeatable Reads: a nonrepeatable read occurs when a transaction reads the same row twice but gets different data each time. For example, suppose transaction 1 reads a row. Transaction 2 updates or deletes that row and commits the update or delete. If transaction 1 rereads the row, it retrieves different row values or discovers that the row has been deleted.
- Phantoms: this is when a row matches the search criteria but is not initially seen. For example, suppose transaction 1 reads a set of rows that satisfy some search criteria. Transaction 2 generates a new row (through either an update or an insert) that matches the search criteria for transaction 1. If transaction 1 reexecutes the statement that reads the rows, it gets a different set of rows.
The defined isolation levels are:
- Read uncommitted: this combines all 3 of the above.
- Read committed: this combines non-repeatable reads and phantoms.
- Repeatable read: (same as above)
- Serializable: none of the above options.
Escape Syntaxes
ODBC provides unified syntaxes for several SQL expressions that typically vary between vendors' implementations: notably,
- Date and Timestamps: historically, a plethora of date and/or time formats has abounded, normally causing much confusion. In ODBC, these things can all be represented in standard format across all RDBMS backend types, as appropriate: * Dates: {d 'yyyy-mm-dd'}
- Times: {t 'hh:MM[:ss.[ffff]]'} (the `f's are optional fraction-of-a-second parts)
- Timestamps: {ts 'yyyy-mm-dd hh:MM[:ss[.ffff]]'}
- Scalar Functions: these encompass string, numeric, date+time, system and conversion functions. For example: {fn DAYOFMONTH(AdateField)} or {fn lcase(aStringField)}.
- Stored Procedures: normally, there is some kind of `exec' syntax with scope for input- and/or output-paramaters. In ODBC, we use {call sp_name (?,?)} and the driver converts it to the native syntax for the current connection.